La Inteligencia Artificial es un campo perteneciente a las Ciencias de la Computación cuyo objetivo es la creación de software y/o hardware inteligente. Entendamos que cualquier sistema basado en hardware y software que pueda realizar exitosamente una tarea no trivial se dice que posee un grado de inteligencia artificial [1]. Una actividad no trivial podría ser: la toma de decisiones financieras, pilotar un helicóptero, desarrollar nuevos productos, realizar un plan de mantenimiento predictivo de máquinas, etc.
Algunas áreas de la Inteligencia Artificial son: teoría de juegos, procesamiento de lenguaje natural, visión por computador, sistemas expertos, búsqueda, reconocimiento de patrones y más.
Cuando en Inteligencia Artificial hablamos de algoritmos genéticos, hablamos de algoritmos de búsqueda inspirados en la teoría de evolución. Un algoritmo es un proceso o conjunto de reglas que permite resolver de manera eficaz un problema. Mejores algoritmos serán eficientes, peores algoritmos sólo serán eficaces.
La Inteligencia Artificial va de la mano del desarrollo tecnológico. Si bien es cierto, la Inteligencia Artificial emergió con fuerza en los 40s con la aparición de las primeras computadoras electrónicas. A medida que la tecnología nos ha ido proporcionando mayor capacidad de procesamiento y almacenamiento, la Inteligencia Artificial ha ido cobrando mayor protagonismo en la solución de problemas complejos. En la actualidad hablamos de sistemas inteligentes capaces de realizar transacciones de compra y venta de acciones en tiempo real, asistentes virtuales de atención al consumidor, aplicaciones orientadas a la fidelización de clientes, etc.
Incluso es muy probable que se haya aplicado la teoría de juegos en las negociaciones entre la Unión Europea y Grecia. La teoría de juegos busca predecir cuál será el resultado más probable en una negociación, ya sea entre personas, empresas o países, donde pueden estar en juego millones de euros. Debemos recordar que todo esto es posible gracias a que somos capaces de convertir en conocimiento la información que extraemos de los datos o del Big Data.
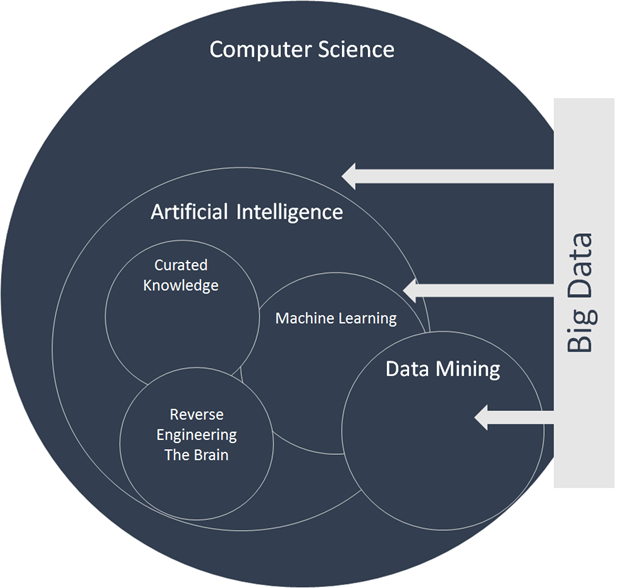
Three main subcategories: machine learning, curated knowledge and reverse engineering the brain. Source: https://www.inovancetech.com/buzzwords.html
Cuando hablamos de Big Data nos referimos a una gran cantidad de datos que sobrepasan las capacidades de procesamiento de las herramientas tradicionales. Podríamos hablar de muchos datos cuando sobrepasan los terabytes pero esto es relativo (recordemos que lo que es Big Data hoy no lo era hace cinco años). Para saber si nos enfrentamos a una problema de big data tenemos que tener en cuenta el volumen (el tamaño de los datos), la velocidad (de llegada y procesamiento) y la variedad (datos de registros web, audio, social media, sensores, etc) [2].
En una organización los datos pueden venir de fuentes internas (por ejemplo: información de diferentes departamentos que incluyen costes, historial de clientes, stock, etc ) y de fuentes externas de información (por ejemplo: lo que dicen mis clientes en una red social). Esto para el sector retail y finanzas puede ser muy útil de cara al desarrollo de nuevos productos e identificación de tendencias.
El sector minero también tiene la necesidad de analizar grandes volúmenes de datos, provenientes de tareas como la prospección, almacenado de información geológica y producción [3]. Tratar los datos como un activo les permite: reducir los costes de mantenimiento y los tiempos no productivos de las máquinas, lo cual repercute positivamente en sus beneficios (hablamos de millones de dólares).
Para realizar el procesamiento de grandes datos podemos hacer uso de procesamiento paralelo, donde muchas máquinas trabajan simultáneamente para resolver un problema, o de computación distribuida, donde distintos dispositivos independientes y conectados en red colaboran para alcanzar una solución. MapReduce es una tecnología que da soporte a la computación paralela y Hadoop es otra tecnología disruptiva que da soporte a la computación distribuida. Además también es posible hacer uso de inteligencia artificial desde la nube.
La computación en la nube (cloud computing), el Big Data y la Inteligencia Artificial, juntas, nos permiten construir una ventana para mirar hacia atrás y adelante. Analizar los datos para simular que pasará o ver los posibles resultados al tomar una decisión es como mirar hacia el futuro, es lo que permite generar ventajas competitivas aunque también implica que las empresas se comprometan y adopten una cultura basada en los datos.
Ahora veamos en un vídeo un ejemplo producido por MIT Senseable City Lab con el BBVA [4].. Traducción de la descripción del vídeo: Una visualización de las transacciones bancarias en tiempo real que nos muestran los patrones de compra durante la Pascua de 2011 en España, y donde 1,4 millones de personas y 374.220 empresas gastaron € 232 millones. Observen que en las gráficas de la izquierda del vídeo aparecen patrones que se repiten como los picos en la compra de alimentos (línea azul) durante los días de vacaciones de Pascua. ¿Para la Pascua de 2012 se replicarán estos patrones de gasto? Si es así, podemos usar esta previsibilidad para mejorar los servicios urbanos y servir mejor a los habitantes de la ciudad?
Referencias
| [1] | Frampton, M. (2014). Big Data Made Easy: A Working Guide to the Complete Hadoop Toolset. Apress. Link de [1]: |
| [2] | Neapolitan, R. E., & Jiang, X. (2012). Contemporary artificial intelligence. CRC Press. Link de [2]: |
| [3] | Matías Gil (2012). La industria minera en búsqueda de la eficiencia con Big Data. América Economía. Link de [3]: |
| [4] | MIT Senseable City Lab with BBVA (2012). SPRING SPREE — spending patterns in spain during easter 2011. Link de [4]: |
Comments
comments powered by Disqus